Implementando Word2Vec com PyTorch

O modelo Word2Vec é uma técnica popular usada para aprender representações vetoriais de palavras. Ele foi introduzido por Mikolov et al. em 2013. O modelo Word2Vec é composto por dois modelos: CBOW (Continuous Bag of Words) e Skipgram. Neste post, vamos implementar o modelo Skipgram com PyTorch.
Dividiremos este post em algumas partes:
- Carregamento e preparação do conjunto de dados
- Criação das tuplas de conjuntos de dados
- Criação do modelo
- Treinamento do modelo
- Exibindo resultados
1. Carregamento e preparação do conjunto de dados
Para nossa tarefa de criar vetores de palavras, usaremos a descrição do enredo do filme da Wikipedia, disponível neste link. Usaremos o seguinte código:
from string import punctuation
import pandas as pd
df = pd.read_csv("data/wiki_movie_plots_deduped.csv")
clear_punct_regex = "[" + punctuation + "\d\r\n]"
corpus = df['Plot'].str.replace(clear_punct_regex, "").str.lower()
corpus = " ".join(corpus)
open("corpus2.txt", "w", encoding="utf8").write(corpus)
Primeiro importamos o pandas para analisar o arquivo csv e depois a variável de pontuação que contém as pontuações comuns usadas em strings.
>> punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
- Na linha 4 carregamos os dados do enredo do filme;
- Na linha 5 construímos a string regex usada para remover pontuações do texto, bem como controlar os caracteres: \n (nova linha), \r (também usado para nova linha) e \d (quaisquer dígitos, 1 2 3 etc.);
- Na linha 6 aplicamos a string regex substituindo cada correspondência por uma string vazia;
- Na linha 7 juntamos todas as linhas das strings dos enredos do filme em uma única linha longa;
- Na linha 8 escrevemos esta longa linha limpa de enredos do filme em um arquivo .txt
Aqui concluímos o carregamento e a limpeza dos dados.
2. Criação das tuplas de conjuntos de dados
corpus = open("data/corpus.txt", encoding="utf8").readlines()
corpus = " ".join(corpus).replace("\n", "")
corpus = corpus.split(" ")
Após criar o arquivo corpus, nós o carregamos e removemos símbolos de terminação de linha dele (\n). Então, nós o dividimos em uma lista de tokens.
from collections import Counter
vocab_cnt = Counter()
vocab_cnt.update(corpus)
vocab_cnt = Counter({w:c for w,c in vocab_cnt.items() if c > 5})
Em seguida, contamos o número de ocorrências de cada palavra e removemos aquelas que ocorrem menos de 5 vezes.
import numpy as np
import random
vocab = set()
unigram_dist = list()
word2id = dict()
for i, (w, c) in enumerate(vocab_cnt.most_common()):
vocab.add(w)
unigram_dist.append(c)
word2id[w] = i
unigram_dist = np.array(unigram_dist)
word_freq = unigram_dist / unigram_dist.sum()
#Generate word frequencies to use with negative sampling
w_freq_neg_samp = unigram_dist ** 0.75
w_freq_neg_samp /= w_freq_neg_samp.sum() #normalize
#Get words drop prob
w_drop_p = 1 - np.sqrt(0.00001/word_freq)
#Generate train corpus dropping common words
train_corpus = [w for w in corpus if w in vocab and random.random() > w_drop_p[word2id[w]]]
No código acima fizemos algumas coisas:
- Criamos uma variável de vocabulário para armazenar todas as palavras que aparecem em nosso corpus;
- Criamos uma variável unigram_dist para acumular o número de ocorrências de cada palavra;
- Criamos um dicionário word2id que nos ajudará a codificar nossas palavras em valores;
- Criamos w_freq_neg_samp, uma distribuição de probabilidade para amostragem de palavras na etapa de amostragem negativa;
- Criamos w_drop_p, uma distribuição de probabilidade para amostragem de palavras que estarão em nossos dados de treinamento;
- Criamos nossos dados de treinamento, descartando algumas palavras com base em w_drop_p.
import torch
#Generate dataset
dataset = list()
window_size = 5
for i, w in enumerate(train_corpus):
window_start = max(i - window_size, 0)
window_end = i + window_size
for c in train_corpus[window_start:window_end]:
if c != w:
dataset.append((word2id[w], word2id[c]))
dataset = torch.LongTensor(dataset)
if USE_CUDA:
dataset = dataset.cuda()
No snippet acima, criamos as tuplas de palavra e palavra de contexto que serão usadas para treinar nosso modelo. Nós as convertemos em tensores de pytorch e anexamos gpus se estiverem disponíveis.
3. Criação do modelo
import torch
from torch import nn, optim
import torch.nn.functional as F
VOCAB_SIZE = len(word2id)
EMBED_DIM = 128
class Word2Vec(nn.Module):
def __init__(self, vocabulary_size, embedding_dimension, sparse_grad=False):
super(Word2Vec, self).__init__()
self.embed_in = nn.Embedding(vocabulary_size, embedding_dimension, sparse=sparse_grad)
self.embed_out = nn.Embedding(vocabulary_size, embedding_dimension, sparse=sparse_grad)
#Sparse gradients do not work with momentum
self.embed_in.weight.data.uniform_(-1, 1)
self.embed_out.weight.data.uniform_(-1, 1)
def neg_samp_loss(self, in_idx, pos_out_idx, neg_out_idxs):
emb_in = self.embed_in(in_idx)
emb_out = self.embed_out(pos_out_idx)
pos_loss = torch.mul(emb_in, emb_out) #Perform dot product between the two embeddings by element-wise mult
pos_loss = torch.sum(pos_loss, dim=1) #and sum the row values
pos_loss = F.logsigmoid(pos_loss)
neg_emb_out = self.embed_out(neg_out_idxs)
#Here we must expand dimension for the input embedding in order to perform a matrix-matrix multiplication
#with the negative embeddings
neg_loss = torch.bmm(-neg_emb_out, emb_in.unsqueeze(2)).squeeze()
neg_loss = F.logsigmoid(neg_loss)
neg_loss = torch.sum(neg_loss, dim=1)
total_loss = torch.mean(pos_loss + neg_loss)
return -total_loss
def forward(self, indices):
return self.embed_in(indices)
w2v = Word2Vec(VOCAB_SIZE, EMBED_DIM, False)
if USE_CUDA:
w2v.cuda()
Na classe acima, definimos nosso modelo pytorch. Ele é composto por duas tabelas de embedding de lookup com inicialização de peso uniforme.
Para treinar nossos embeddings, usaremos Negative Sampling. Na função neg_samp_loss, calculamos a seguinte quantidade:
\[J = -(\log \sigma({v'_{w_O}}^\top \cdot v_{w_I}) + \sum_{i=1}^{k} \mathbb{E}_{wi \sim Pn(w)} [\log \sigma(-{v'_{w_I}}^\top \cdot v_{w_I})])\]O termo \(\log \sigma({v'_{w_O}}^\top \cdot v_{w_I})\) é referente as linhas 23 a 26.
O termo \(\sum_{i=1}^{k} \mathbb{E}_{wi \sim Pn(w)} [\log \sigma(-{v'_{w_I}}^\top \cdot v_{w_I})]\) é referente as linhas 28 e 33.
def get_negative_samples(batch_size, n_samples):
neg_samples = np.random.choice(len(vocab), size=(batch_size, n_samples), replace=False, p=w_freq_neg_samp)
if USE_CUDA:
return torch.LongTensor(neg_samples).cuda()
return torch.LongTensor(neg_samples)
Aqui definimos nossa função para gerar alvos negativos a serem usados em nosso objetivo durante o treinamento.
optimizer = optim.Adam(w2v.parameters(), lr=0.003)
Aqui apenas definimos o otimizador que executará nossas atualizações de peso.
4. Treinamento do modelo
def get_batches(dataset, batch_size):
for i in range(0, len(dataset), batch_size):
yield dataset[i:i+batch_size]
Esta função é usada para gerar nossos lotes durante o loop de treinamento.
n_epochs = 5
n_neg_samples = 5
batch_size = 512
for epoch in range(n_epochs): # loop over the dataset multiple times
loss_values = []
start_t = time.time()
for dp in get_batches(dataset, batch_size):
optimizer.zero_grad() # zero the parameter gradients
inputs, labels = dp[:,0], dp[:,1]
loss = w2v.neg_samp_loss(inputs, labels, get_negative_samples(len(inputs), n_neg_samples))
loss.backward()
optimizer.step()
loss_values.append(loss.item())
ellapsed_t = time.time() - start_t
#if epoch % 1 == 0:
print("{}/{}\tLoss: {}\tEllapsed time: {}".format(epoch + 1, n_epochs, np.mean(loss_values), ellapsed_t))
print('Done')
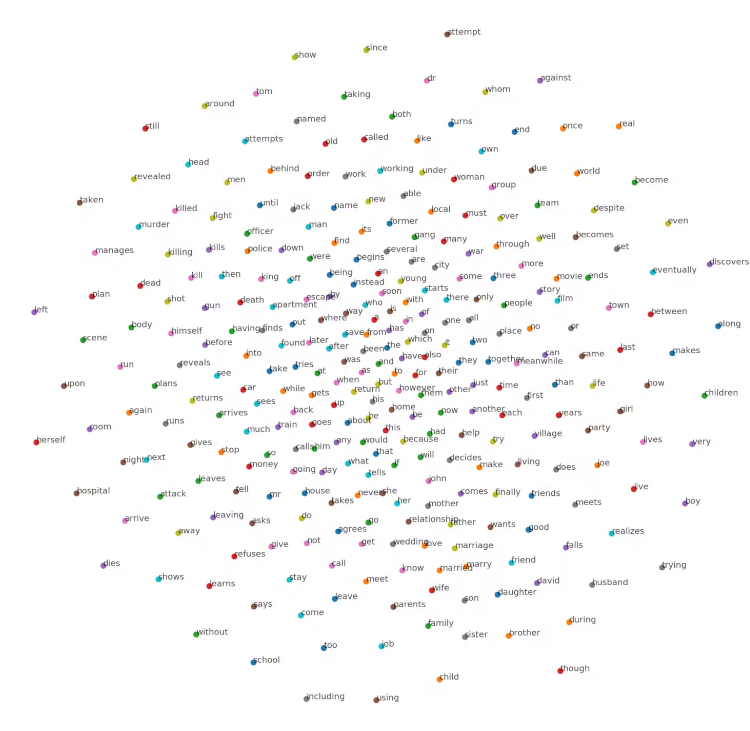
5. Exibindo resultados
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
data_viz_len = 300
viz_embedding = w2v.embed_in.weight.data.cpu()[:data_viz_len]
tsne = TSNE()
embed_tsne = tsne.fit_transform(viz_embedding)
plt.figure(figsize=(16,16))
for w in vocab[:data_viz_len]:
w_id = word2id[w]
plt.scatter(embed_tsne[w_id,0], embed_tsne[w_id,1])
plt.annotate(w, (embed_tsne[w_id,0], embed_tsne[w_id,1]), alpha=0.7)