Análise de Sentimentos — Redes Neurais
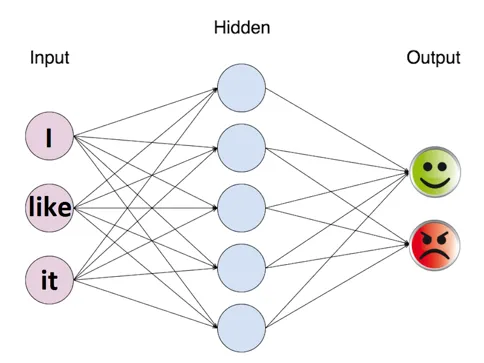
Na próxima série de tópicos, vamos mergulhar em diferentes abordagens para resolver o problema do Olá Mundo da NLP, a análise de sentimentos.
O código esta disponível aqui.
O código
Usaremos duas bibliotecas de aprendizado de máquina:
- scikit-learn para criar vetores onehot a partir do nosso texto e dividir o conjunto de dados em treinamento, teste e validação;
- tensorflow para criar a rede neural e treiná-la.
Nosso conjunto de dados é composto por resenhas de filmes e rótulos que informam se a resenha é negativa ou positiva. Vamos carregar o conjunto de dados:
O arquivo de reviews é um pouco grande, então está em formato zip. Vamos extraí-lo com o modulo zipfile:
import zipfile
with zipfile.ZipFile("reviews.zip", 'r') as zip_ref:
zip_ref.extractall(".")
Agora que temos os arquivos reviews.txt e labels.txt , vamos carregá-los na memória:
with open("reviews.txt") as f:
reviews = f.read().split("\n")
with open("labels.txt") as f:
labels = f.read().split("\n")
reviews_tokens = [review.split() for review in reviews]
Em seguida, carregamos o módulo para transformar nossas entradas de revisão em vetores binários com a ajuda da classe MultiLabelBinarizer:
from sklearn.preprocessing import MultiLabelBinarizer
onehot_enc = MultiLabelBinarizer()
onehot_enc.fit(reviews_tokens)
Depois disso, dividimos os dados em conjunto de treinamento e teste com a train_test_split função. Então, dividimos o conjunto de teste pela metade para gerar um conjunto de validação:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(reviews_tokens, labels, test_size=0.4, random_state=None)
split_point = int(len(X_test)/2)
X_valid, y_valid = X_test[split_point:], y_test[split_point:]
X_test, y_test = X_test[:split_point], y_test[:split_point]
Em seguida, definimos duas funções:
label2bool, para converter a string label em um vetor binário de dois elementos, eget_batch, que é um gerador para retornar partes do conjunto de dados em uma iteração:
def label2bool(labels):
return [[1,0] if label == "positive" else [0,1] for label in labels]
def get_batch(X, y, batch_size):
for batch_pos in range(0,len(X),batch_size):
yield X[batch_pos:batch_pos+batch_size], y[batch_pos:batch_pos+batch_size]
O Tensorflow conecta expressões em estruturas chamadas graphs. Primeiro limpamos qualquer graph existente, depois obtemos o comprimento do vocabulário e declaramos placeholders que serão usados para inserir nossos dados de texto e rótulos:
import tensorflow as tf
tf.reset_default_graph()
vocab_len = len(onehot_enc.classes_)
inputs_ = tf.placeholder(dtype=tf.float32, shape=[None, vocab_len], name="inputs")
targets_ = tf.placeholder(dtype=tf.float32, shape=[None, 2], name="targets")
Esta postagem não pretende ser um tutorial do tensorflow. Para mais detalhes, visite https://www.tensorflow.org/get_started/
Criamos então nossa rede neural:
- h1 é a camada oculta que recebeu como entrada os vetores de palavras de texto;
- logits é a camada final que recebe o h1 como entrada;
- output é o resultado da aplicação da função sigmóide aos logits;
- loss é a expressão de loss para calcular o erro atual da rede neural;
- optimizer é a expressão para ajustar os pesos da rede neural a fim de reduzir a expressão loss;
- correct_pred e accuracy são usados para calcular a precisão atual da rede neural variando de 0 a 1.
h1 = tf.layers.dense(inputs_, 500, activation=tf.nn.relu)
logits = tf.layers.dense(h1, 2, activation=None)
output = tf.nn.sigmoid(logits)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=targets_))
optimizer = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(targets_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')
Em seguida, treinamos a rede, imprimindo periodicamente sua precisão e perda atuais:
epochs = 10
batch_size = 3000
sess = tf.Session()
# Initializing the variables
sess.run(tf.global_variables_initializer())
for epoch in range(epochs):
for X_batch, y_batch in get_batch(onehot_enc.transform(X_train), label2bool(y_train), batch_size):
loss_value, _ = sess.run([loss, optimizer], feed_dict={
inputs_: X_batch,
targets_: y_batch
})
print("Epoch: {} \t Training loss: {}".format(epoch, loss_value))
acc = sess.run(accuracy, feed_dict={
inputs_: onehot_enc.transform(X_valid),
targets_: label2bool(y_valid)
})
print("Epoch: {} \t Validation Accuracy: {}".format(epoch, acc))
test_acc = sess.run(accuracy, feed_dict={
inputs_: onehot_enc.transform(X_test),
targets_: label2bool(y_test)
})
print("Test Accuracy: {}".format(test_acc))
Epoch: 0 Training loss: 0.6979156732559204
Epoch: 0 Validation Accuracy: 0.5709999799728394
Epoch: 1 Training loss: 0.5234161019325256
Epoch: 1 Validation Accuracy: 0.7129999995231628
Epoch: 2 Training loss: 0.4143674373626709
Epoch: 2 Validation Accuracy: 0.8370000123977661
Epoch: 3 Training loss: 0.27750399708747864
Epoch: 3 Validation Accuracy: 0.8650000095367432
Epoch: 4 Training loss: 0.20388154685497284
Epoch: 4 Validation Accuracy: 0.8740000128746033
Epoch: 5 Training loss: 0.1524941474199295
Epoch: 5 Validation Accuracy: 0.8840000033378601
Epoch: 6 Training loss: 0.10476348549127579
Epoch: 6 Validation Accuracy: 0.8640000224113464
Epoch: 7 Training loss: 0.08236084133386612
Epoch: 7 Validation Accuracy: 0.859000027179718
Epoch: 8 Training loss: 0.06472384929656982
Epoch: 8 Validation Accuracy: 0.8820000290870667
Epoch: 9 Training loss: 0.04698138311505318
Epoch: 9 Validation Accuracy: 0.8930000066757202
Test Accuracy: 0.902999997138977
Com essa rede, obtivemos uma precisão de 90% ! Com mais dados e usando uma rede maior, podemos melhorar esse resultado ainda mais!